


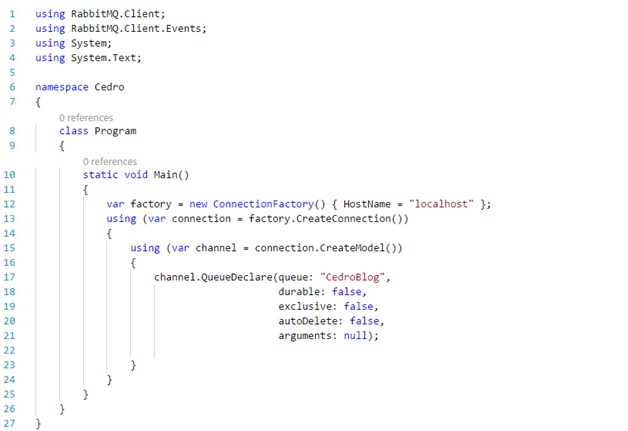
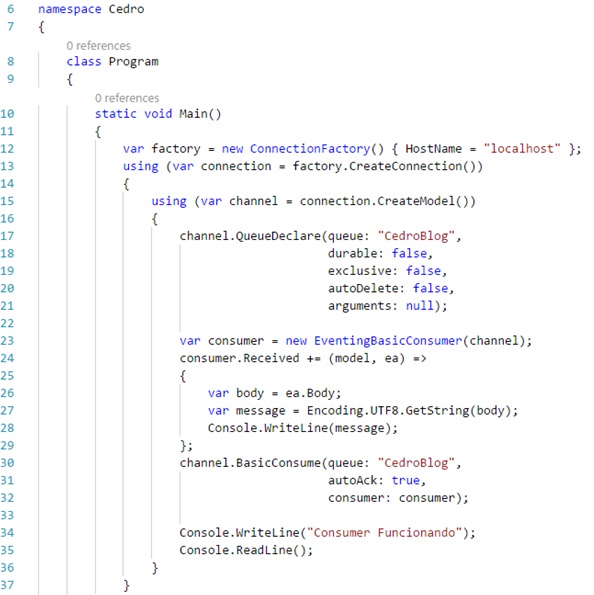
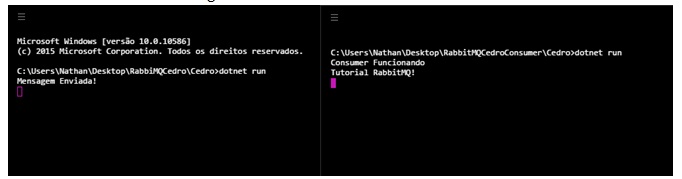



A Cedro Technologies utiliza cookies para melhorar a sua experiência de navegação, personalizar conteúdos e desenvolver iniciativas de marketing. Para informações sobre os tipos de cookies e para configurá-los de acordo com a sua preferência, clique em “Definições de cookies”, onde poderão ser habilitados e desabilitados conforme sua preferência. Para aceitá-los, clique em "Aceitar todos os cookies". Querendo saber mais, acesse nossa Política de Privacidade.
Aviso de Cookies
Cookies estritamente necessários
Os cookies estritamente necessários permitem um funcionamento adequado do nosso site, não coletando ou armazenando informações sobre você ou em relação às suas preferências. Normalmente, eles só são configurados em resposta a ações realizadas pelos usuários, como por exemplo salvar as suas preferências de privacidade, realizar login ou salvar informações para o preenchimento de formulários. Por essa razão, não é possível desabilitá-los.
Se você desativar este cookie, não poderemos salvar suas preferências. Isso significa que toda vez que você visitar este site, você precisará ativar ou desativar os cookies novamente.
Cookies de desempenho (Performance cookies)
Esse tipo de cookie coleta informações sobre como os usuários utilizam e navegam no site, como por exemplo:
- Quais páginas os usuários acessam com mais frequência;
- Se o usuário recebe mensagens de erro de nossas páginas.
Vale ressaltar que esse tipo de cookie não coleta informações que identificam o usuário. Todas as informações que esses cookies coletam são agregadas e, portanto, anônimas, sendo usados apenas para melhorar o funcionamento do site (medição e melhoria de desempenho do site).
Ative primeiro os Cookies estritamente necessários para que possamos salvar suas preferências!
Cookies de funcionalidade (Functional cookies)
Permitem que o site forneça funcionalidade e personalização aprimoradas. Eles podem ser definidos por nós ou por fornecedores terceiros cujos serviços adicionamos às nossas páginas.
Ative primeiro os Cookies estritamente necessários para que possamos salvar suas preferências!